Tensorflow alapozó 5.
Visszacsatolt hálózatok és LSTM
A visszacsatolás fogalmával fősulin találkoztam először. Ráadásul nem is a mesterséges intelligenciával kapcsolatban, hanem digitális technika órán. Ez a tantárgy arról szólt, hogy hogyan lehet logikai kapukból (ÉS/VAGY/NEM) logikai áramköröket összerakni. Minden digitális áramkör, ide értve a legbonyolultabb mikroprocesszorokat is ilyen pár tranzisztoros logikai kapukból épül fel. A logikai hálózatok egyszerűbbik változata a kombinációs hálózat. Ez egy olyan doboz, aminek van egy bináris bemenete, valamint egy bináris kimenete, és a kimenet csakis a bemenettől függ. Igazából ez a konstrukció nagyon hasonlít az eddig megismert neurális hálókra, azzal a különbséggel, hogy a neurális hálózat be- és kimenete nem bináris, valamint hogy a kombinációs hálózattal ellentétben a neurális hálózat tanítható. Kombinációs hálózattal sokmindent meg lehet oldani. Építhetünk belőle például összeadó vagy akár szorzó áramkört, de hamar beleüközünk a korlátaiba. A kombinációs hálózatnak ugyanis nincs “emlékezete”. Ez azt jelenti, hogy ahogyan az előbbiekben írtam, a kimenet csakis a bemenettől függ, nincs rá hatással semmilyen régebbi történés. Ez gondot jelent például akkor, ha egy számláló áramkört szeretnénk készíteni, aminek a bemenetére impulzusok érkeznek, a kimenete pedig az összeszámolt impulzusok száma. Ez nem túl bonyolult feladat, de egy kombinációs hálózatnak gondot jelent, hiszen “emlékzet” híján mindig elfelejti, hogy hol tartott a számolásban. Szerencsére a probléma könnyen orvosolható. A hálózat kimenetét (vagy annak egy részét) vissza kell csatolni a bemenetére. Ennek köszönhetően a bemenet most már nem csak az impulzus, hanem a számláló előző állapota is, ami alapján a kombinációs hálózat ki tudja számolni a következő állapotot. A visszacsatolás által tehát “emlékezetet” nyernek a hálózatok amivel lehetőség nyílik időben változó bemenetek kezelésére. A visszacsatolás lehetősége tehát rendkívűl fontos tulajdonsága egy hálózatnak. Olyannyira, hogy a visszacsatolt kombinációs hálózatoknak külön nevet is adtak: ezek a sorrendi hálózatok. Valójában bármilyen digitális áramkör amit valaha terveztek vagy tervezni fognak, a legegyszerűbb számlálótól a legbonyolultabb mikroprocesszorig leképezhető ilyen sorrendi hálózatra. A visszacsatolás az, ami a logikai hálózatokat univerzális eszközökké teszi! Nos, pont ugyanez igaz a neurális hálózatokra is. Elméletileg bármilyen létező algoritmus leképezhető visszacsatolt neurális hálózatra, legyen az valamilyen számítógépes játék végigjátszása, vagy akár az emberi agy modellezése a jövőben.
Ennyi elmélet után nézzünk egy egyszerű kódot. A “Hello World!” karaktersorozatot fogjuk betanítani egy hálózatnak, mégpedig oly módon, hogy mindig az előző karakterből jósoljuk a következőt. Tehát ha a bemenet “H”, a kimenet “e” lesz, ha a bemenet “e”, a kimenet “l” lesz, stb. Visszacsatolás nélkül erre nem lennénk képesek, mivel ez esetben a kimenet csak a bemenettől függene, így minden karakterhez csakis egy másik karakter tartozhatna. Ez láthatóan problémát okozna az “l” betű esetén, hiszen az első esteben az “l” betű után egy másik “l” betű jön, a második esetben “o” betű, a harmadik esetben pedig “d”. A hálózatnak tehát “emlékeznie” kell arra, hogy hol tart a szövegben.
A fenti kód egyes részei ismerősek lehetnek a cikksorozat 3. részében épített autoencoderből. Mindkét esetben one hot vektorok képzik a be és kimeneteket, csak míg a 3. részben szavakból képeztük a vektorokat, itt az egyes karakterek jelentik a szótárat.
A source_data-ba és a target_data-ba kerülnek a bemenetek és a kimenetek one hot kódolással. Mindkét tenzor 11x9-es méretű, mivel a szótárunk (egyedi karakterek) mérete 9 elem, a szöveg pedig 12 karakter hosszú (és mivel minden karakterhez a következőt rendeljük, 11 db ilyen összerendelésünk lesz).
Van még 2 expand_dims sor, ami egy plusz dimenzióval 3 dimenziósra bővíti az előző 2 dimenziós tenzorainkat. Erre azért van szükség, mert a SimpleRNN réteg (hamarosan lesz szó róla részletesen) [batch size, timesteps, input dim] formában várja a bemenetet. Az eddigi (nem visszacsatolt) példákhoz képest tehát bejött egy új dimenzió, a timesteps. Mikor elkezdtem ismerkedni a visszacsatolt hálókkal, engem nagyon zavart, hogy más a bemenet formátuma. Azt gondoltam, hogy egy visszacsatolt háló csupán annyiban fog különbözni egy nem visszacsatolt hálótól, hogy miközben tömöm bele az adatokat, nem felejti el az állapotat. De a dolog nem ilyen egyszerű. Egy nem visszacsatolt hálózatnál a backpropagation a bementig kell csak hogy visszamenjen, mivel a kimenet csakis a bemenettől függ. Egy visszacsatolt hálózatnál azonban az eredmény függhet az előző állapot kimenetétől, ami az előző állapot bemenetétől függ, valamint függhet az azt megelőző állapottól is, stb. egészen a legelső időpillanatig. Egy ilyen visszacsatolt hálózatnál tehát a backpropagationnek nem elég visszamenni a bemenetig, időben is vissza kell mennie. Éppen ezért a backpropagation ezen változatát szokták backpropagation through time-nak is hívni. Logikailag olyan az egész, mint ha megismételnénk az egész hálózatot annyiszor, ahányi időpillanatot visszamegyünk, és erre a “kihajtogatott” hálózatra futtatnánk le a backpropagationt.
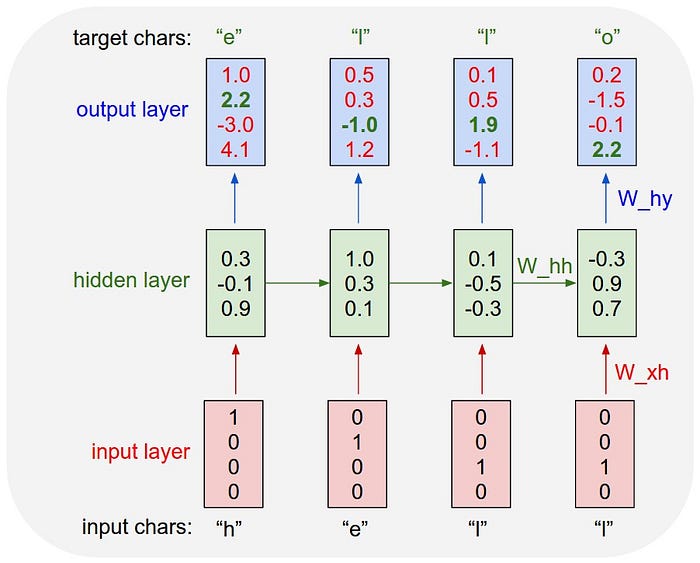
A fenti képen látszik egy ilyen hálózat az elő 4 időpillanatra kihajtogatva. Minden ciklusban van egy bemenet, egy kimenet, és egy állapot, ami a következő ciklus bemenetét képzi a hálózat bemenete mellett. Ezen a kihajtogatott hálón kell végigtolni a backpropagationt, hogy megfelelően álljanak be a súlyok. A kérdés már csak az, hogy hány ciklust menjen vissza a backpropagation? Itt jön a képbe a timestamps dimenzió. Ahány cikluson keresztül szeretnénk visszaterjeszteni a hibát, annyit kell belepakolnunk a tenzorunkba. Nem lehet tehát “folyamatosan tanítani” a hálót. Ehelyett “kell csinálnunk egy felvételt” a minátkról, majd azt vagy annak egy szakaszát egyben odaadni a hálózatnak. A tanító algoritmus csak ezt az átadott részt látja a folyamatból és erre futtatja le a backpropagationt.
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_1 (SimpleRNN) (None, 11, 4) 56
_________________________________________________________________
dense (Dense) (None, 11, 9) 45
=================================================================
Total params: 101
Trainable params: 101
Non-trainable params: 0
_________________________________________________________________A kód következő része a hálózat definiálása. A hálózatunk két rétegből áll. Az első egy SimpleRNN réteg, ami egy egyszerű visszacsatolt háló, ami jelen esetben 4 neuronból áll és minden neuronnak 9 bemenete van. Ez valójában 13 (9+4) bemenet neurononként, mivel a 9 bemenet mellé jön a 4 neuron visszacsatolt kimenete, plusz egy bias. Ennek a rétegnek tehát összesen 56 (4*14) paramétere lesz. Ezt követi egy sima teljesen csatolt réteg, ami 4 bemenettel (plusz 1 bias) és 9 kimenettel rendelkezik, így 45 (5*9) paramétere van. Ennek a cellának a kimeneti fv.-e softmax, mivel azt várjuk tőle, hogy megmondja, melyik karakter következik legnagyobb valószínűséggel az előzőek függvényében. A hálózat valójában nagyon hasonlít a 3. részben megismert autoencoderhez, csak itt a 4 dimenziós kimenet a 9 dimenziós bemenet mellett az előző állapot 4 dimenziós vektorától is függ. Ez valósítja meg azt a fajta emlékezetet, ami képessé teszi a hálózatot a “Hello World!” karaktersorozat megtanulására.
A SimpleRNN réteggel és úgy általában a visszacsatolással van egy nagy probléma. Ahogy haladunk az időben, egyre inkább “elkopik” az információ (Vanishing gradient problem). Megoldásként olyan “okos memóriákat” találtak ki, mint az LSTM vagy a GRU.

A fenti ábrán látható az LSTM elvi felépítése. Dióhéjban annyit kell róla tudni, hogy a SimpleRNN-el ellentétben nem simán a bemenetből és a kimenetből képzi a kimenetet, hanem a bemenettől függően tárolja a kimenetet, amit csak a megfelelő bemenet hatására töröl. Összességében tehát tényleg olyasmi mint egy memória cella, ami hosszú távon képes megjegyezni dolgokat. Akit bővebben érdekel az LSTM működése, az itt talál róla egy jó összefoglaló cikket. Az LSTM tehát képes kiküszöbölni azt a fajta “információ kopást” ami a SimpleRNN-nél problémát jelentett. Andrej Karpathy szavaival élve olyan mint egy cső vagy szupersztráda amin az adatok gond nélkül közlekedhetnek a multból a jövő felé.
A GRU az LSTM kistestvére. Eggyel kevesebb paraméterrel rendelkezik, így kevesebb számítási kapacitás kell a tanításához, úgyanakkor sok esetben az LSTM-el megegyező teljesítményt nyújt. A GRU használatára jó példa a Tensorflow text generation tutorialja, ahol egy 1024 GRU cellás hálózatnak tanítanak be Shakespeare szövegeket hasonlóan karakter alapon, ahogyan mi is tettük. Annyi a csavar a dologban, hogy a következő karaktert mindig véletlenszerűen választják a jósolt valószínűség alapján, így a hálózat minden futtatás után más-más szöveget generál. A dolog érdekessége, hogy az eredmény minden esetben a szavak szintjén szinte hibátlan angol szöveg lesz. Ez azért elég nagy dolog azt figyelembe véve, hogy csupán karakter statisztikákat tanítottunk a hálózatnak.
Andrej Karpathy egy hasonló hálózatot használva a Linux kernel forrását tanította be egy neurális hálónak, ami így egész értelmes C kódokat generált. Bár maga a kód értelmetlen, jól látható a mintában, hogy a szintaktikát (a C nyelv nyelvtanát) egész jól megtanulta. Egy ilyen hálózatnak már lehet gyakorlati haszna például egy intelligens kódkiegészítő formájában.
Végül ide linkelném még az OpenAI Dota hálózatának diagramját, ami “super human” szinten képes játszani a játékot és ugyancsak kulcsfontosságú része egy 1024 LSTM cellából álló réteg.
Jól látható tehát, hogy a visszacsatolt hálózatokban rengeteg a lehetőség szinte minden területen, legyen az idősorok elemzése, számítógépes játékok, vagy akár robotok vezérlése. Mivel visszacsatolt hálók segítségével elvileg bármilyen aloritmus megvalósítható, itt van kezünkben az univerzális eszköz, a kérdés, hogy mi mindenre leszünk képesek általa.
Ha tetszett az írás, olvasd el az előző részeket is:
A következő részt pedig itt találod: